Ruixiang Li
Lecture11:The Memory Hierarchy存储器系统结构
Storage technologies and trends
Random-Access Memory(RAM)
大多数人熟悉的内存是RAM:随机访问存储器,通常被打包为芯片,多个芯片组合起来成为主存。
最基本的存储单元被称为Cell 单元,每个单元存储一个bit。
RAM可以分为两种,通过存储单元的实现方式区分:
-
SRAM(Static RAM,静态随机存取存储器),晶体管,速度快但昂贵,不需要充电(但是需要保持通电),集成度低。
-
DRAM(Dynamic RAM,动态随机存取存储器),一个晶体管+一个电容,每隔一段时间要刷新充电一次,否则数据会消失;但集成度高,相同容量下体积更小。
(EDC:error detection and correction,错误检测与矫正)
| 1bit所需晶体管数 | Access Time | 需要刷新? | 需要EDC? | 成本 | 应用 | |
|---|---|---|---|---|---|---|
| SRAM | 4 or 6 | 1x | No | Maybe | 100x | Cache Memories |
| DRAM | 1 | 10x | Yes | Yes | 1x | Main memories,frame buffers |
SRAM和DRAM在断电后都会丢失数据
Nonvolatile Memories(NVM)非易失性内存
非易失性存储器即使断电也能保留数据
-
只读存储器(ROM):在生产过程中已编程,可以使用20-30年;
-
可编程只读存储器(PROM):可编程一次。
-
可擦除的 PROM(EPROM):可通过紫外线或 X 射线大量擦除。
-
电可擦除 PROM(EEPROM):可通过电子方式擦除。
-
闪存:EEPROM 的一种,支持部分(块级别)擦除。但是在大约 100,000 次擦除后会磨损。
非易失性存储器的用途
-
存储固件程序在 ROM(如 BIOS、磁盘控制器、网络卡、图形加速器、安全子系统等)。
-
固态硬盘Solid State Disks(替代旋转硬盘,用于 U 盘、智能手机、MP3 播放器、平板电脑、笔记本电脑等)。
-
磁盘缓存。
Traditional Bus Structure Connecting CPU and Memory传统总线结构
总线(BUS):一组并行的导线,用于传输地址、数据和控制信号。总线通常被多个设备共享。
总线连接CPU中的寄存器组、算术逻辑单元ALU、接口等,系统中总线分为系统总线(System Bus) 和内存总线(Memory Bus),数据流可以在内存和 CPU 芯片之间通过总线往返传输,过程中通常经过 I/O 桥接器(Inter称为芯片组chipset)。
(注:只是一种简易的抽象)
Memory Read/Write Transaction
movq A, %rax
执行movq指令时,CPU会将A的地址存放到存储器主线上,主存接收信号后,从该地址取得一个8字节的字的内容返回总线,通过I/O桥回到总线接口,然后CPU从总线数据中读取这个字,放到寄存器%rax中。
movq %rax, A
写入过程同理,CPU将地址写入总线,主存读取后,CPU将%rax的内容放到总线上,传输到主存完成存放。
寄存器非常接近ALU,所以寄存器读写非常快;而内存是非常远离CPU的一些芯片组,对内存的读写通常需要50~100ns,而寄存器只需要<1ns。
硬盘通过机械结构读写数据,磁盘几何结构(Disk Geometry):
-
磁盘由多片盘片(platters) 组成,每个盘片有两个表面(surfaces)。
-
每个表面由多个同心圆环组成,称为磁道(tracks)。
-
每个磁道分为多个扇区(sectors),扇区之间由间隙(gaps) 隔开,通常一个扇区存储512bytes。
-
在主轴上,盘片、轨道相互对齐。轨道的集合称为一个柱面。
磁盘的容量(Capacity) 为其可以存储的最大比特数,单位:千兆字节GB=10^9字节。影响容量的技术因素有(其实只有前两个):
| 因素 | 单位 | 定义 |
|---|---|---|
| 记录密度 Recording density |
bits/in 比特/英寸 |
在磁道的 1 英寸段内可以存储的比特数。 |
| 磁道密度 Track density |
tracks/in | 在半径方向 1 英寸区域内可容纳的磁道数量。 |
| 面密度 Areal density |
bits/in^2 比特/平方英寸 |
记录密度和磁道密度的乘积。 |
HDD
现代磁盘结构:
现代磁盘将磁道分割成不相交的子集,称为记录区(recording zones)。
特点:
-
每个记录区中的所有磁道具有相同数量的扇区,扇区数量由该区最内侧磁道的周长决定。
-
不同的记录区有不同数量的扇区/磁道。外部记录区的磁道拥有更多的扇区,相比之下内部记录区的磁道扇区较少。
-
计算磁盘容量时,通常使用每磁道扇区数量的平均值(average number of sectors per track)。
磁盘容量 = 每个扇区存储的字节数 * 磁盘每磁道的平均扇区数 * 每个磁盘表面上的磁道总数 * 每片盘片的表面数量 * 磁盘中的总盘片数量。
比如对于:每个扇区512字节、每磁道平均300扇区、每表面20000磁道、每盘片2表面、5张盘片,总容量为:
512 * 300 * 20000 * 2 * 5 =30.72GB.
磁盘以固定的速度逆时针旋转(通常7200转/min),磁臂沿半径轴前后移动,以定位到不同磁道。在多个磁盘的情况下,每个盘面上都有磁臂,每个表面都有一个读/写头。
磁盘读取数据的时间包括:移动磁头的寻道时间Seek、等待旋转的旋转延迟Rotational latency(平均为磁盘旋转半周的时间)、轨道在读写头下通过的传输时间Transfer time。
寻道时间(3-9ms,机械限制)平均在5ms; 平均旋转延迟=1/2 * 1/RPM * 60s/min,大约为4.17ms(转速7200RPM); 平均传输时间=1/RPM * 1/每个磁道上平均的扇区数 * 60s/min,300扇区时大约为0.00278ms。总访问时间为9.17ms。
读取一个double的数据时,SRAM约4ns、DRAM约60ns,而Disk比SRAM慢40000倍、比DRAM慢约2500倍。
现代磁盘通过将可用扇区建模为一系列大小为 b 的逻辑块(0,1,2,……),简化了复杂的扇区几何结构,其中逻辑块与实际物理扇区之间的映射由称为磁盘控制器的硬件或固件设备管理,该控制器将逻辑块的请求转换为(磁面、磁道、扇区)三元组;此外,控制器还可以为每个区域预留备用柱面,以应对“格式化容量”和“最大容量”之间的差异。
I/O Bus(10年的PCI总线2333)
现代系统使用PCI Express总线结构,是点对点的结构,不同于广播总线。
当读取磁盘扇区是时,CPU会编写一个三元组来启动读取,包括指令、逻辑块号、内存地址。
磁盘控制器读取与该逻辑块对应的扇区,然后取得总线的控制权,通过I/O桥复制数据到I/O总线,直接复制到主存储器,而不通知CPU(即DMA,direct memory access直接存储器访问)。
一旦其将数据传输到主存储器,就会通过 “interrupt”(“中断”) 机制通知CPU,即在CPU的一个引脚上将值从0变为1(从进程阻塞态变为就绪态),通知CPU该扇区已经复制。
现在CPU可以执行该程序并处理内存。(详情见《计组》)
- 理由?
磁盘读取速度太慢!10ms系统可以执行数百万次指令,不可能让CPU停下来等待磁盘读取。
SSDs(Solid State Disks固态)
SSD大概处于HDD和DRAM中间,在CPU看来其与HDD完全相同,具有相同的物理接口和包装,但SSD完全由闪存构建。
在SSD中有一组固件:flash translation layer闪存翻译层,作用与HDD的磁盘控制器相同。
数据可以以 Page页 为单位从闪存读写数据,从512KB到4KB。
一系列的页形成 Block块 ,有32-128页,不同于CPU理解的逻辑块。一个页只能在所属的整个块都被擦除后才能写这一页。
在经过大约100,000次写入/擦除后,这个块就会磨损。
现代SSD通过各种专用算法以延长SSD的寿命,如Caching缓存等。(花里胡哨)
- Characteristics特点:
| 性能指标 | 吞吐量/时间 |
|---|---|
| 顺序读取吞吐量 (Sequential read tput) | 550 MB/s |
| 随机读取吞吐量 (Random read tput) | 365 MB/s |
| 平均顺序读取时间 (Avg seq read time) | 50 µs |
| 顺序写入吞吐量 (Sequential write tput) | 470 MB/s |
| 随机写入吞吐量 (Random write tput) | 303 MB/s |
| 平均顺序写入时间 (Avg seq write time) | 60 µs |
顺序访问比随机访问更快:
-
顺序访问速度更快是内存层次结构中的常见特性。
-
原因是顺序访问可以充分利用硬件的连续性设计和缓存机制。
随机写入速度相对较慢:
-
擦除一个块所需时间较长(~1 毫秒)。
-
修改块中的一个页面时,需要将该块的所有其他页面一起复制到新的块中(因为 SSD 写入操作的 “擦除” 机制)。
-
在早期的 SSD 中,读取和写入速度差距更大,但现代 SSD 已显著优化这一问题。
对比SSD和HDD:
优势:速度更快、功耗更低、更坚固(不知道为什么用rugged)
缺点:容易磨损、成本更高(指每字节存储成本,截至2015)
应用:MP3 players、智能手机、laptop,桌面端和服务器已有出现。
Locality of reference局部性
CPU-Memory gap:CPU处理数据速度和存储器读写数据速度之间的巨大鸿沟。为了弥合 CPU-Memory gap,关键是程序的局部性Locality。
局部性:程序倾向于使用其地址接近或等于最近使用过的数据和指令和那些数据和指令。
Programs tend to use data and instructions with addresses near or equal to those they have used recently.
通常局部性有两种形式:
-
Temporal locality时间局部性:指最近引用的存储器位置可能在不久的将来再次被引用;
-
Spatial locality空间局部性:指引用临近存储器位置的倾向。
example:
sum = 0;
for(int i = 0; i < n; i++)
sum += a[i];
return sum;
数据部分:
-
连续引用数组元素(被称为步长为1的引用模式stride-1 reference pattern)(空间局部性)
-
每次循环重复使用
sum变量(时间局部性)
指令部分:
-
按顺序引用指令(空间局部性)
-
重复循环遍历(时间局部性)
定性估计Qualitative Estimates
应该避免程序出现差的局部性。
突然想到“奥卡姆剃刀定律”(Occam’s Razor, Ockham’s Razor)
“如无必要,无增实体。”,即“简单有效原理”。
算不算好的局部性体现?
经典案例:二维数组遍历,先行后列 和 先列后行
Caching in the memory hierarchy
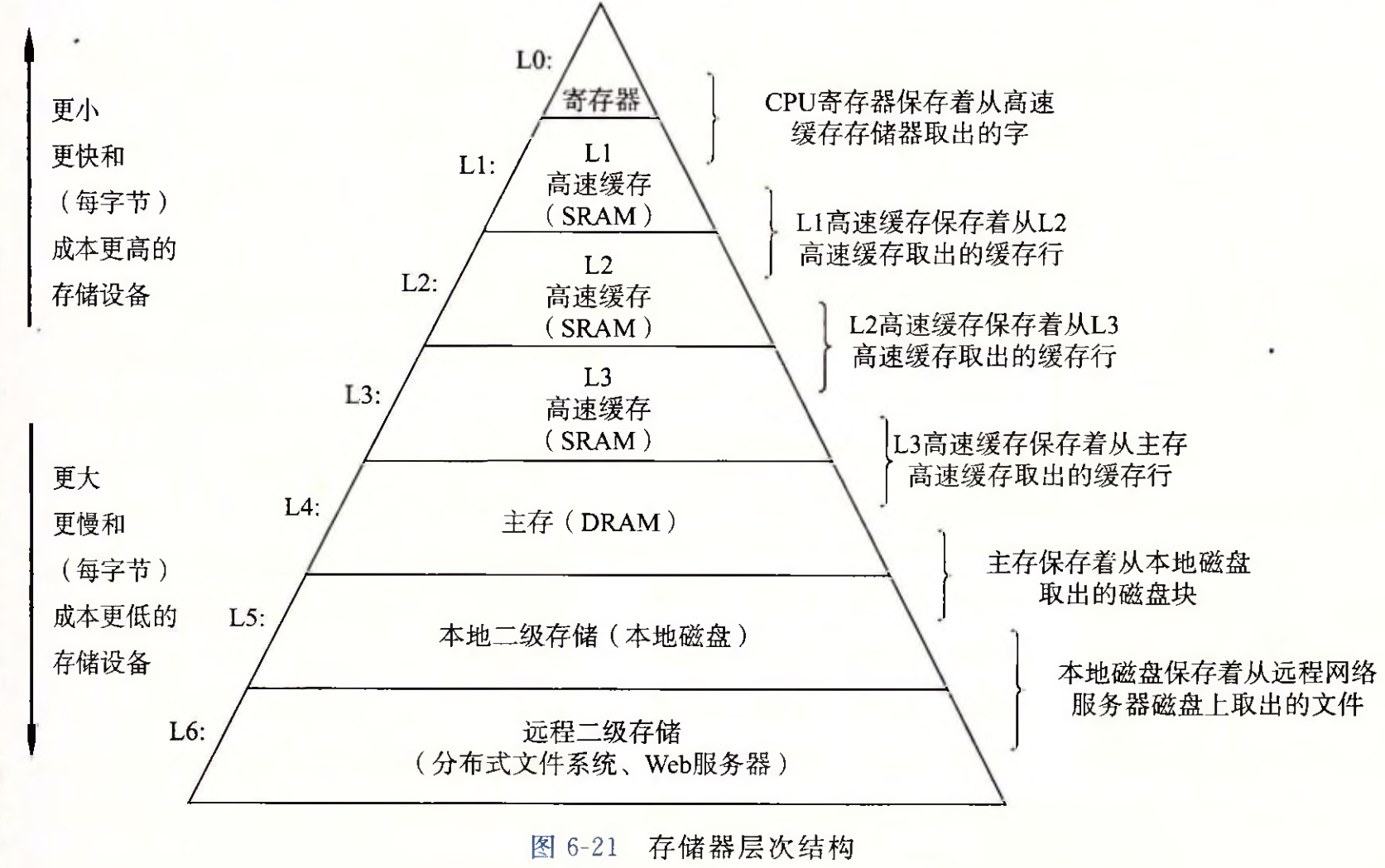
MemoryHierarchy存储层次结构
快速存储技术的每字节成本更高,容量更小,并且需要更多电力(产生更多热量!);CPU 和主存储器速度之间的差距正在扩大;编写良好的程序往往表现出良好的局部性。
这些基本特性相互完美补充。它们为组织存储器和存储系统提供了一种被称为存储层次结构的解决方法。
在这个层次的顶端有更小、更快、更昂贵的存储设备,即L0:寄存器Regs。其在每一个CPU周期均可以被访问;
接下来是由SRAM组成的L1:L1缓存cache、L2:L2缓存cache和L3:L3缓存cache,大小为MB。(L1离CPU最近,且为每个核心独占;L3则是多核心共享)
再向下就是L4:主存Main Memory,由DRAM构成;之后是L5:本地存储器(Local secondary storage);最后是L6:远程存储(Remote secondary storage)。
存储器层次结构中,每一级都包含从下一低级层次所检索的数据。
Caches高速缓存
缓存是一种更小更快的存储设备,作为更慢设备中数据的暂存区域。
由于局部性存在,程序往往倾向于访问更高级的数据,所以低级的存储设备可以更慢但是更大。
General Cache Concepts
以“块”为单位将数据复制到内存中,保证CPU可以快速访问这些数据。
1.Hit
如果CPU需要的数据正好在缓存中,则可以直接将块返回CPU,即缓存命中。
2.Miss
如果CPU需要的数据不在缓存中,称为缓存未命中(Cache Miss)。Cache从主存中去除所需块,并返回CPU。具体可以分为几种:
-
Cold(compulsory) miss:冷不命中/强制不命中:即初始缓存中没有任何数据和块。
-
Conflict miss:冲突不命中:大多数缓存将 k+1 层的块限制在 k 层块位置的一个小子集(有时是单个位置)中,例如:k+1 层的块 i 必须放置在 k 层的块 (i mod 4) 中。 当 k 层缓存足够大,但多个数据对象都映射到同一个 k 层块时,就会发生冲突不命中。例如:引用块 0、8、0、8、0、8 …… 每次都会不命中。
-
Capacity miss:容量不命中:即CPU请求的数据量超过了Cache的容量,需要更大的缓存。 我们称这样不断被访问的块为工作集(Working set),工作集的大小和内容随程序而变,当他超过Cache的容量就会发生容量不命中。
Example:
| Cache Type | What is Cached? | Where is it Cached? | 延迟(cycles) | 由__管理 |
|---|---|---|---|---|
| Registers | 4-8 bytes words | CPU core | 0 | Compiler |
| TLB | Address translations | On-Chip TLB | 0 | Hardware MMU |
| L1 cache | 64-byte blocks | On-Chip L1 | 4 | Hardware |
| L2 cache | 64-byte blocks | On-Chip L2 | 10 | Hardware |
| Virtual Memory | 4-KB pages | Main memory | 100 | Hardware + OS |
| Buffer cache | Parts of files | Main memory | 100 | OS |
| Disk cache | Disk sectors | Disk controller | 100,000 | Disk firmware |
| Network buffer cache | Parts of files | Local disk | 10,000,000 | NFS client |
| Browser cache | Web pages | Local disk | 10,000,000 | Web browser |
| Web cache | Web pages | Remote server disks | 1,000,000,000 | Web proxy server |
(注:TLB,Translation Lookaside Buffer,即旁路转换缓冲或地址转换后备缓冲,用于加速虚拟地址到物理地址的转换过程。)
(NFS:Network File System,网络文件系统;AFS:Andrew File System,安德鲁文件系统)